


Two years ago, when I started building HeyDo, I thought the hardest problems in AI were technical.
Turns out, they’re philosophical.
Because the more time I spend working on HeyDo& ShareAI, the more I realize this field isn’t just about faster models, smarter agents, or cooler demos.
How do we build systems that understand purpose—and act accordingly?
The Two Camps
Right now, the AI world is splitting.
One camp is betting big on Mixture-of-Experts (MoE)—massive models with internal routing. The idea is simple: build a huge network of “experts” inside a monolith, and let the model figure out which part to activate based on the task.
It’s efficient. It scales. And it feels like a natural evolution of the current LLM landscape.
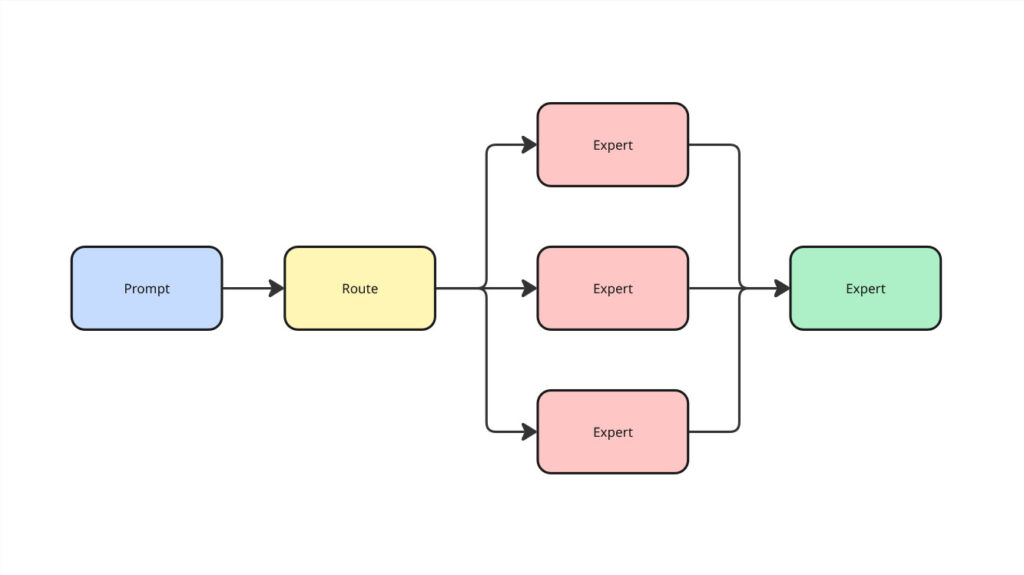
The other camp is going the opposite way—toward specialization. Multiple smaller models, each trained for a specific domain or task, working together in a kind of orchestration.
This side bets on modularity, composability, and fine-tuned performance.
Both paths make sense. Both are being validated in real time.
But what if we’re missing something in the middle?
What If It’s Not Either/Or?
What if the real future of AI isn’t about choosing one approach over the other—but merging them?
What if the next wave of intelligence isn’t about bigger models or smaller agents—but smarter routing of purpose?
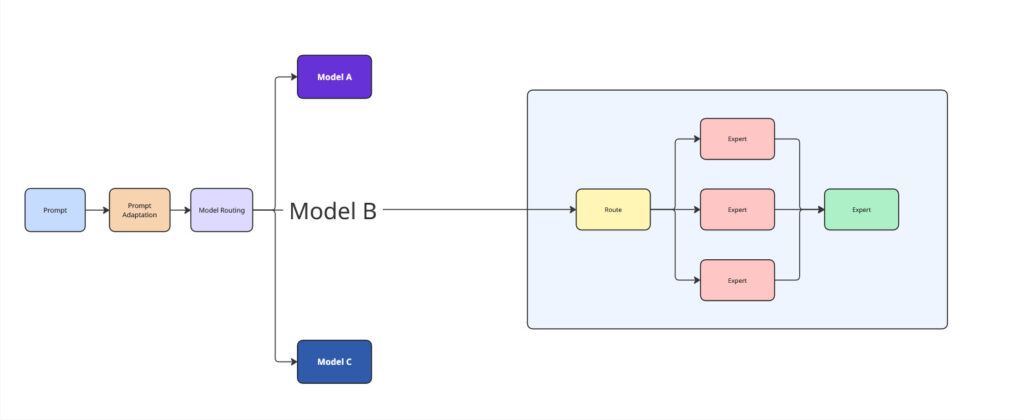
Imagine a system that receives a prompt—not just as text, but as intent. It interprets the request, breaks it down, and routes each part to the most capable model. Along the way, it adapts the prompt itself, reshaping it for context, clarity, and outcome.
Not monolith. Not fragmentation. But orchestration with understanding.
That’s the kind of intelligence we should be building. And that’s the direction we’re taking with ShareAI.
Routing with Purpose
In version 0.0.7 of ShareAI, we’re introducing automatic model routing and prompt adaptation.
It’s a small feature. But it hints at something much larger: a world where intelligence isn’t just centralized or decentralized—it’s contextual.
Where the intelligence isn’t just in the model—but in the flow between models.
Where prompts aren’t blindly passed along—but actively understood, interpreted, and evolved.
Credit Where It’s Due
This wouldn’t be possible without the brilliant work of Tomás Hernando, who not only developed the most elegant routing approach I’ve seen—but is committed to open-sourcing it.
We’re standing on the shoulders of people who believe in making hard problems public goods. And we intend to keep building that way.
You can explore the foundation here: notdiamond.ai
What Comes Next
This isn’t the end goal. It’s just a waypoint.
But it’s one that matters—because the way we route intelligence says everything about the kind of future we want to build.
Big. Modular. Smart. Orchestrated. Human-aware.
The future belongs to those brave enough to rethink what intelligence even means.
Let’s keep building.
— Denis
#BuildingTomorrowToday
Legend
What is a monolith?
A single, large AI model that handles all tasks internally—like GPT-4, Claude, or Gemini. Everything happens within one architecture.
What is Mixture-of-Experts (MoE)?
An AI model design that activates only a subset of internal “experts” for each task. It makes large models more efficient by using only what’s needed.
What is model routing?
Directing a prompt or task to the most suitable model from a collection, based on what the input is trying to achieve.
What is prompt adaptation?
Automatically rephrasing or structuring a user’s input so it fits the expectations or optimal format of the model it’s being sent to.
What is notdiamond.ai?
An open-source project by Tomás Hernando focused on intelligent model routing—helping prompts find the right model with precision and purpose.
https://www.notdiamond.ai
What is ShareAI?
A decentralized marketplace for AI models where anyone can contribute idle compute power and earn—or become a full-time AI provider.
One API call gives access to every model served by a global peer-to-peer grid.
https://shareai.now



